
نقشهی دنیای یادگیری ماشین
اگر حوصله خواندن مطالب طولانی را ندارید، برای فهمیدن مفاهیم به تصویر زیر نگاهی بیندازید.
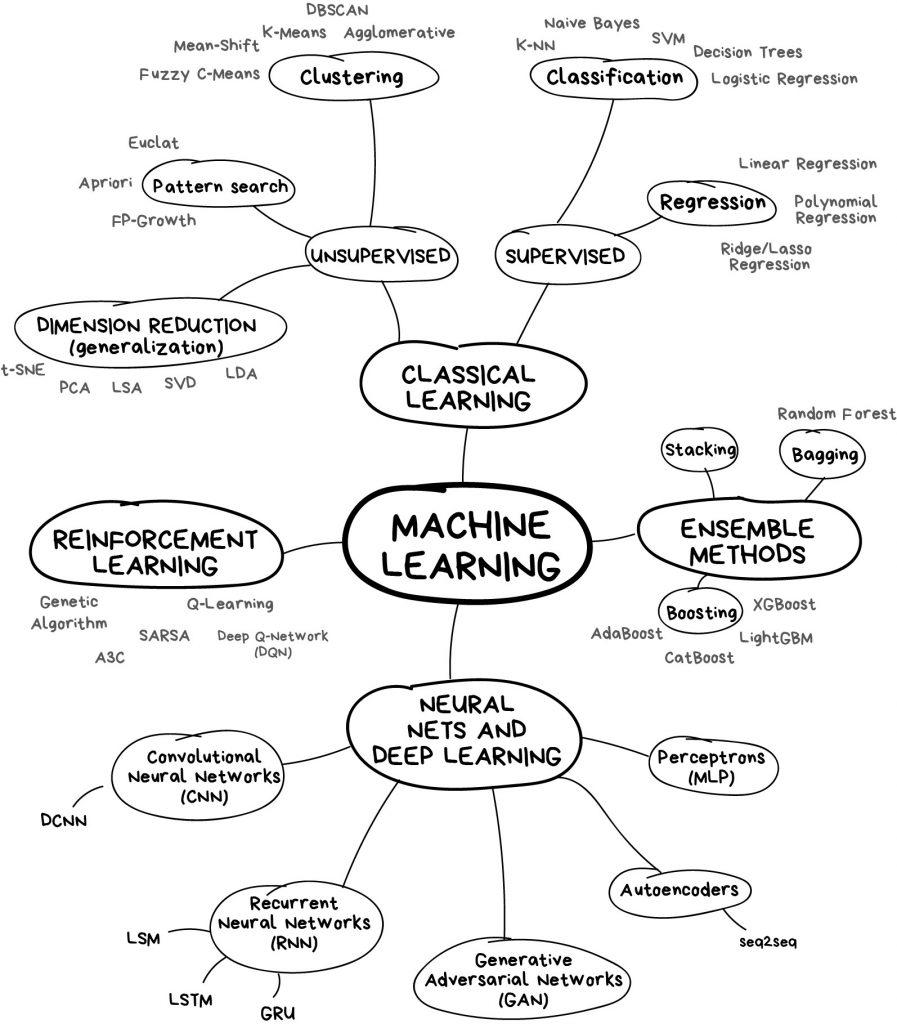
یکی از نکات مهمی که همواره باید به خاطر داشت این است که برای هر مساله در دنیای یادگیری ماشین، فقط و فقط یک راهحل وجود ندارد. معمولا چندین الگوریتم مناسب برای مساله وجود دارد و شما باید انتخاب کنید که کدام یک از آنها بهتر است. بیشک همه مسائل را میتوان با شبکههای عصبی حل کرد اما چه کسی هزینهی تامین GeForceها را پرداخت کند. [برای استفاده از شبکههای عصبی نیاز به پردازندههای بسیار قوی است و GeForce یکی از این پردازندهها است که محصول شرکت Nvidia است؛ مترجم].
بیایید با مرور کلی دنیای یادگیری ماشین شروع کنیم. امروزه چهار شاخه اصلی در یادگیری ماشین وجود دارد.
۱- یادگیری ماشین کلاسیک (Classical Machine Learning)
اولین روشهای یادگیری ماشین در دهه ۵۰ میلادی از آمار نظری پدید آمدند. آنها مسالههای ریاضی آکادمیک مانند جستجوی الگوها (patterns) در اعداد، محاسبهی نزدیکی نقطه دادهها ( proximity of data points) و محاسبه جهت بردارها (vectors) را حل کردند.
امروزه نیمی از اینترنت بر اساس این الگوریتمها کار میکنند. وقتی موقع خواندن اخبار و مقالات با انتخاب گزینهی “بعدی” فهرستی از اخبار و مقالات به شما نشان داده میشود یا وقتی کارتتان توسط بانک به دلایل امنیتی و به خاطر استفاده در پمپ بنزینی وسط ناکجاآباد مسدود میشود، احتمالا کار یکی از همین رفقای فسقلی است.
شرکت های بزرگ فناوری طرفدار دو آتیشه شبکههای عصبیاند. برای آنها بهبود ۲ درصدیِ دقت مدل به معنای افزایش ۲ میلیاردیِ درآمد است. اما برای شرکتهای کوچک چنین موضوعی منطقی به نظر نمیرسد. من داستانهایی درباره تیمهایی شنیدهام که یک سال از وقت خود را صرف پیادهسازی الگوریتم جدیدی کردهاند تا در صفحهی اصلی وب سایت، محصولاتی را برای خرید به کاربران پیشنهاد کند و بعد از یک سال متوجه شدهاند که ۹۹٪ ترافیک سایت از موتورهای جستجو میآید. الگوریتمهای پیادهسازیشده عملا بیفایده بودند چون بیشتر کاربران حتی صفحه اصلی سایت را باز نمیکردند.
با وجود محبوبیت، رویکردهای کلاسیک آن قدر سادهاند که می توان آنها را به راحتی به کودکان توضیح داد. آنها شبیه ریاضیات پایهاند و ما بدون آنکه فکرمان را درگیر آنها کنیم، هر روز از آنها استفاده می کنیم.
۱.۱- یادگیری تحت نظارت (Supervised Learning)
یادگیری ماشین کلاسیک اغلب به دو دسته تقسیم میشود: یادگیری تحت نظارت (Supervised Learning) و یادگیری بدون نظارت (Unsupervised Learning)
در یادگیری تحت نظارت، ماشین یک «سرپرست»(supervisor) یا «معلم»(teacher) دارد که تمام پاسخها را در اختیارش قرار میدهد برای مثال برای هر عکس مشخص میکند که این عکسِ گربه است یا عکس سگ. معلم قبلاً دادهها را به دو دستهی عکس گربهها و عکس سگها تقسیم کرده است (برچسب یا label زده است ). و ماشین از این نمونهها برای یادگیری استفاده میکند: یکی یکی و سگها جدا گربهها جدا.
یادگیری بدون نظارت به این شکل است که انبوهی از عکس حیوانها را در اختیار ماشین قرار میدهیم و وظیفهی ماشین این است که به تنهایی و بدون معلم، عکس هر حیوانی (عکسهای مشابه) را پیدا کند. در این روش، دادهها برچسب (label) ندارند و معلمی هم وجود ندارد، ماشین تلاش میکند تا به تنهایی الگوها را پیدا کند. در مورد این روشها در ادامه صحبت خواهیم کرد.
بدیهی است که ماشین با کمک معلم سریعتر یاد خواهد گرفت از این رو در کارهای (task) واقعی بیشتر از یادگیری تحت نظارت استفاده میشود. این کارها (tasks) به دو دسته تقسیم میشوند: طبقهبندی (classification) که در آن، دستهای که یک شی (object) به آن تعلق دارد پیشبینی میشود و رگرسیون (regression) که در آن، نقطهای معین روی محورهای عددی پیشبینی میشود.
مترجم: خانم سپیده مشایخی
گزیده:
«اگر بخواهم پیام این کتاب را در یک عبارت مختصر و مفید بیان کنم این است که شما باهوشتر از دادههایتان هستید. دادهها نمیتوانند علت و معلول (causes and effects) را درک کنند، اما انسانها میتوانند.»
– جودیا پرل، کتاب چرا: علم جدید علت و معلول


محمد کدخدائی
۲۰ تیر ۱۴۰۱ در ۲۲:۳۲با سلام،
واقعا عالی، امید که سایر الگوریتمها رو هم برای تکمیل به این تصویر اضافه کنید که همین الان چند هیچ از خیلی مقالات و کتابها کاملتره ????????
یوسف مهرداد
۲۸ تیر ۱۴۰۱ در ۲۰:۱۴سلام آقای کدخدایی عزیز
ممنون از پیشنهاد شما. اگر ایدهای دارید لطفا بفرمایید در حد مقدورات حتما پیگیری خواهم کرد تا انجام شوند. جهت اطلاع عرض کنم که فعلا هدف این است که متن اصلی به فارسی برگردان شود و در نتیجه تنها الگوریتمهایی که در متن اصلی هستند در این نوشتار خواهند آمد.
شاد باشید.
محمد
۳۰ تیر ۱۴۰۱ در ۱۷:۴۲سلام مجدد،
ممنون از توجه شما، به عنوان مثال میشود نسخه ای از این تصویر را در xmind ارائه کنید که بتوان روشهای خوشه بندی (مبتنی بر افراز، چگالی و …) را با جزئیات بیشتر به همراه الگوریتمهای هر کدام مشخص تر کرد. برای تازه کارها قطعا چنین تقسیم بندی هایی کمک کننده خواهد بود.
سپاس
یوسف مهرداد
۱ مرداد ۱۴۰۱ در ۰۲:۱۸ممنون از راهنمایی شما.
شاد باشید