
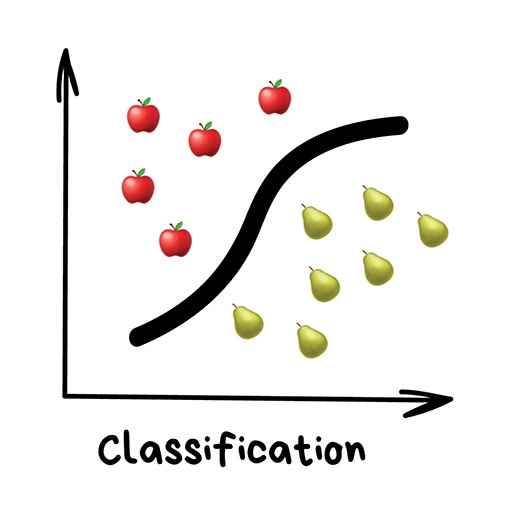
۱-۱-۱-طبقهبندی (Classification)
تعریف: طبقهبندی عبارت است از تقسیم اشیاء بر اساس یکی از خصیصههای (attribute) از پیش تعیینشده. برای نمونه تقسیم جورابها بر اساس رنگ آنها، تقسیم اسناد و مدارک بر اساس زبان نوشتاری یا تقسیم آهنگها بر اساس ژانر (genre) آنها
کاربردها:
– شناسایی و فیلتر هرزنامه (Spam filtering)
– تشخیص زبان (Language detection)
– پیدا کردن اسناد مشابه (A search of similar documents)
–تحلیل احساسات (Sentiment analysis)
– شناسایی حروف و اعداد دستنویس (Recognition of handwritten characters and numbers)
– تشخیص تقلب (Fraud detection)
الگوریتمهای محبوب:
– بیز ساده (Naive Bayes)
– درخت تصمیم (Decision Tree)
– رگرسیون لجستیک (Logistic Regression)
– کی-نزدیکترین همسایه (K-Nearest Neighbors یا K-NN)
– ماشین بردار پشتیبان (Support Vector Machine یا SVM)
از اینجا به بعد میتوانید با اطلاعات خود در مورد این بخشها اظهار نظر کنید. اگر دوست داشتید میتوانید نمونهها و مثالهای خود را دربارهی هر یک از کارها و وظایف (task) یادگیری ماشین بیان کنید. این بخش بر اساس تجربیات شخصیام نوشته شده است.
یادگیری ماشین معمولا درباره طبقهبندی موضوعات است. در طبقهبندی، ماشین مانند کودکی است که در حال یادگیری مرتب کردن اسباب بازیهای خود است: این یه رباته، این هم یه ماشینه، (با دیدن ماشین بدون راننده) این هم یه … این چیه؟ … اوه! اوه! صبر کنید. اشتباهه! اشتباهه!
در طبقهبندی، شما همواره به یک معلم نیاز دارید. دادهها باید با ویژگیها (features) برچسبگذاری شوند تا ماشین بتواند دستهها (class) را بر اساس آنها تعیین کند. همه چیز را میتوان طبقهبندی کرد: طبقهبندی کاربران را بر اساس علایق (مانند کارکرد فیدهای الگوریتمی) (مترجم. فیدهای الگوریتمی یا algorithmic feed، الگوریتمهای شبکههای اجتماعیاند که مطالب مورد علاقهی کاربر را پیشبینی میکنند. به عبارت دیگر به جای نمایش پستهای جدید به ترتیب زمان انتشار آنها، شبکه اجتماعی مطالبی را به کاربر نشان میدهد که بر اساس علایق وی پیشبینی و انتخاب کرده است) ، طبقهبندی مقالات بر اساس زبان و موضوع (topic) (که برای موتورهای جستجو با اهمیت است) ، طبقهبندی موسیقی مبتنی بر ژانر (مانند لیست پخش Spotify) و حتی طبقهبندی ایمیلهای شما.
در شناسایی و فیلتر هرزنامهها از الگوریتم بیز ساده (Naive Bayes ) به شکل گستردهای استفاده شده است. ماشین تعداد تکرار نام یک واژه غیرمجاز را در هرزنامهها و ایمیلهای عادی میشمارد و احتمال (probability) آنها را حساب میکند. سپس با استفاده از معادله بیز آنها را ضرب و جمع انجام میدهد و تعیین میکند که پیام دریافتی هرزنامه است یا یک پیام عادی. خوب تمام شد و ما به یک مدل یادگیری ماشین دست پیدا کردیم (مترجم. اساس معادله بیز، احتمال شرطی است که در آن از دادههایی مانند احتمال وجود یک کلمه در پیامهای عادی و در هرزنامهها و همچنین احتمال اینکه یک پیام، هرزنامه باشد یا پیام عادی استفاده میشود).
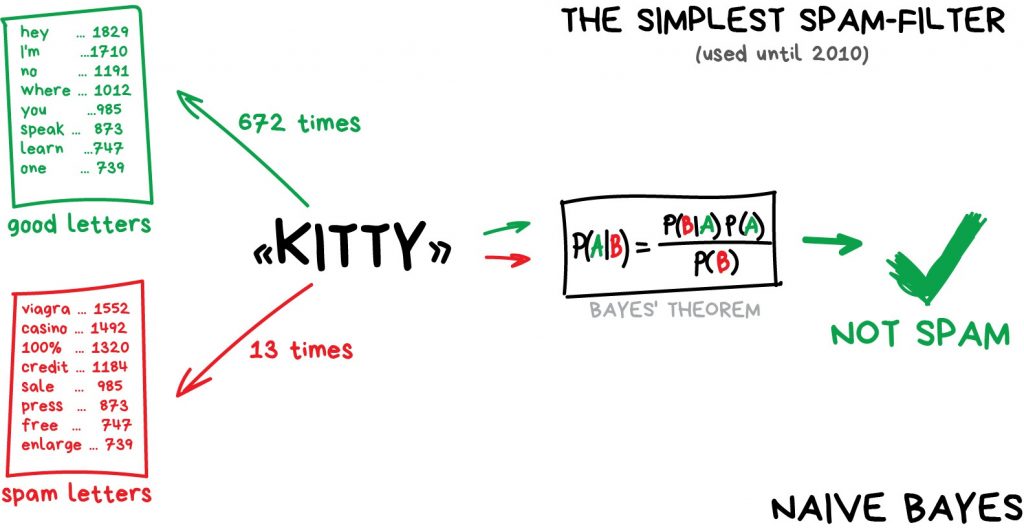
بعدها ارسالکنندگان هرزنامه یاد گرفتند که چگونه با افزودن تعداد زیادی کلمه «خوب» در پایان ایمیل، فیلترهای بیز رو به رو شوند. به کنایه به این روش، مسمومیت بیز (Bayesian poisoning) گفته میشود. بیز ساده به عنوان ظریفترین و از نظر کاربردی اولین الگوریتم در تاریخ ثبت شد. اما اکنون از الگوریتم های دیگر برای شناسایی و فیلتر هرزنامهها استفاده میشود.
مترجم: خانم سپیده مشایخی
گزیده:
بهترین شطرنجبازان جهان، نه رایانهها هستند و نه انسانها، بلکه انسانهایی هستند که با رایانهها کار میکنند.
جان بروکمن
منبع: کتاب تراوشهای ذهنی، ۲۵ شیوه نگرش به هوش مصنوعی

دیدگاهتان را بنویسید